Hadoop empowers us to solve problems that require intense processing and storage on commodity hardware harnessing the power of distributed computing, while ensuring reliability. When it comes to applicability beyond experimental purposes, the industry welcomes Hadoop with warm heart, as it can query their databases in realistic time regardless of the volume of data. In this post, we will try to run some experiments to see how this can be done.
Before you start, make sure you have set up a Hadoop cluster. We will use Hive, a data warehouse to query large data sets and a adequate-sized sample data set, along with an imaginary database of a travelling agency on MySQL; the DB consisting of details about their clients, including Flight bookings, details of bookings and hotel reservations. Their data model is as below:

The number of records in the database tables are as:
- booking: 2.1M
- booking_detail: 2.1M
- booking_hotel: 1.48M
- city: 2.2K
We will write a query that retrieves total country-wise bookings with a hotel reservation, paid in USD or GBP, distributed by booking type for each country.
select c.city_title, d.booking_type, count(*) total from booking b
inner join booking_detail d on d.booking_id = b.booking_id
inner join booking_hotel h on h.booking_id = b.booking_id
inner join city c on c.city_code = d.city_code where b.currency in ('GBP','USD')
group by c.city_code, d.booking_type
This query takes 150 seconds on MySQL to execute. We will try to reduce the query execution time by importing the dataset on Hive and executing the same query on our Hadoop cluster. Here are the steps:
Importing Data
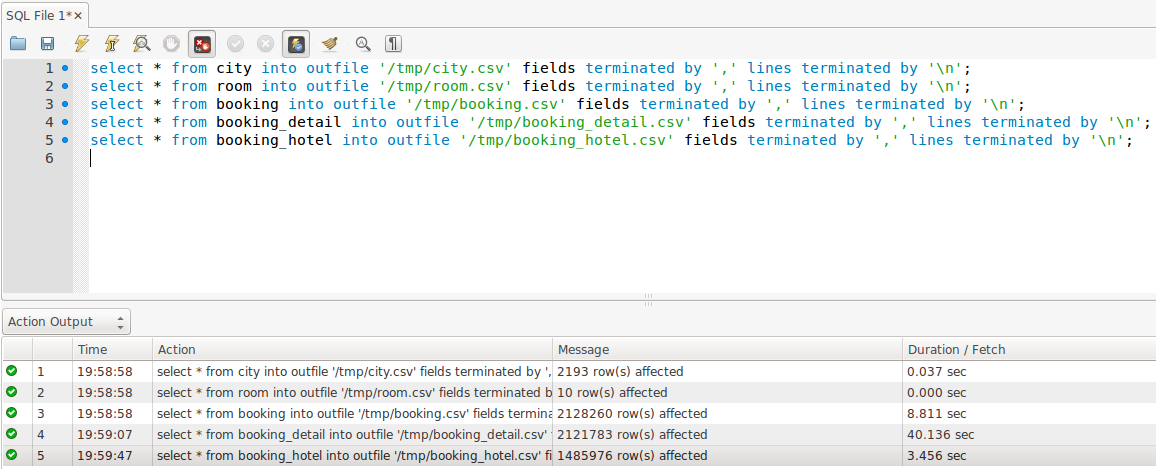
First step is to export the tables in the database CSV files. Open MySQL Workbench in your master (assuming you have MySQL Server and Workbench installed and have exported the data set in it) and execute the following queries:
select * from city into outfile '/tmp/city.csv' fields terminated by ',' lines terminated by '\n';
select * from booking into outfile '/tmp/booking.csv' fields terminated by ',' lines terminated by '\n';
select * from booking_detail into outfile '/tmp/booking_detail.csv' fields terminated by ',' lines terminated by '\n';
select * from booking_hotel into outfile '/tmp/booking_hotel.csv' fields terminated by ',' lines terminated by '\n';
This will export the tables in /tmp directory as CSV files.
Installing Hive
We now install Hive on our Hadoop-ready machine. Download hive-0.11.0 from Apache Hive’s downloads
Extract into /home/hadoop/Downloads directory
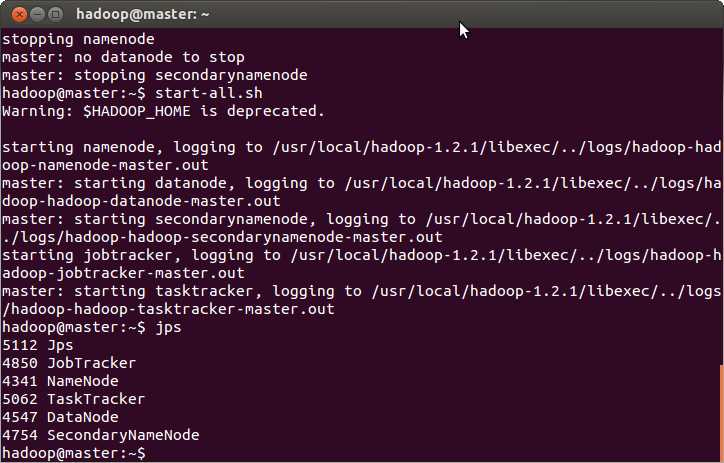
Start Hadoop services and disable safemode:
$ start-all.sh
$ hadoop dfsadmin -safemode leave
$ jps
Copy Hive binaries and libraries into /usr/local director (or wherever you wish to install):
$ sudo cp -R /home/hadoop/Downloads/hive-0.11.0/ /usr/local/
Create a temporary directory in HDFS and a warehouse directory for Hive:
$ hadoop fs -mkdir /tmp
$ hadoop fs -mkdir /hadoop/hive/warehouse
Assign rights:
$ hadoop fs -chmod g+w /tmp
$ hadoop fs -chmod g+w /hadoop/hive/warehouse
Export environment variable for Hive:
$ export HIVE=/usr/local/hive-0.11.0
Run hive:
$ $HIVE/bin/hive
Preparing Hive Database
We will now create tables in Hive DB. Note that there are certain Hive data types that are different from traditional DBMS data types. In addition, we have specified that the fields are terminated by coma, as well as the format, in which the data will be saved. This is because Hive has separate data structures to process different formats of data. Now create the tables identical to the schema by executing following queries:
hive>create table booking (booking_id int, currency string, departure_date string, requested_date string) row format delimited fields terminated by ',' stored as textfile;
hive>create table booking_detail (booking_id int, deetails_id int, booking_type string, item_code string, item_name string, passenger_count int, city_code string, duration int, price float, breakfast string, description string) row format delimited fields terminated by ',' stored as textfile;
hive>create table booking_hotel (booking_id int, details_id int, room_type string, room_cat string) row format delimited fields terminated by ',' stored as textfile;
hive>create table city (city_code string, city_title string, country string) row format delimited fields terminated by ',' stored as textfile;

Next step is to load the data from the CSV files into Hive tables. Execute the following commands to do so:
hive>load data local inpath '/tmp/city.csv' overwrite into table city;
hive>load data local inpath '/tmp/booking.csv' overwrite into table booking;
Make sure that all tables are in place.
hive>show tables;
Now execute a query to count the number of records in booking table:
hive>select count(*) from booking;
This will execute a MapReduce job against the given query; the query took 24.5 seconds, which may seem to be surprising to you. This is because the first time, Hive initiates a lot of things, creates some files in temp directory, etc. We will execute the same query again; this time, it took 14.3 seconds. Still, this is very high time for a simple count query. This needs some explanation.
First of all, MySQL and other RDBMSs are optimized to run queries faster using techniques like Indexing, etc. On the other hand, Hive is to run queries on Hadoop framework, which is a distributed computing environment. Therefore, the time it takes to distribute the data, interpret the query, create MapReduce tasks respectively is where the time is consumed most.
Second, a simple count query is not the type of query we should run on distributed environment, as it can easily be handled by RDBMS itself. The real performance impact will be shown when we run a complex query that processes data in large volume.
Now run the same query, which MySQL executed in 150 seconds:
hive>select c.city_title, d.booking_type, count(*) total from booking b inner join booking_detail d on d.booking_id = b.booking_id inner join booking_hotel h on h.booking_id = b.booking_id inner join city c on c.city_code = d.city_code where b.currency in ('GBP','USD') group by c.city_code, d.booking_type;

The query takes 132.84 seconds on single node on Hive. This is because the MapReduce job breaks the original query into pieces, thus leveraging all cores of the CPU to process data in parallel.
We can try the same by increasing number of mappers and reducers. To do so, first quit Hive:
hive>quit;
Shut down Hadoop's services
$ stop-all.sh
Edit the mapred-site.xml file in
$ sudo nano /usr/local/hadoop/conf/mapred-site.xml
Add two properties to the file:
<property>
<name>mapred.map.tasks</name>
<value>20</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>5</value>
</property>

Save the file and exit; start all Hadoop services and Hive again; run the same query.
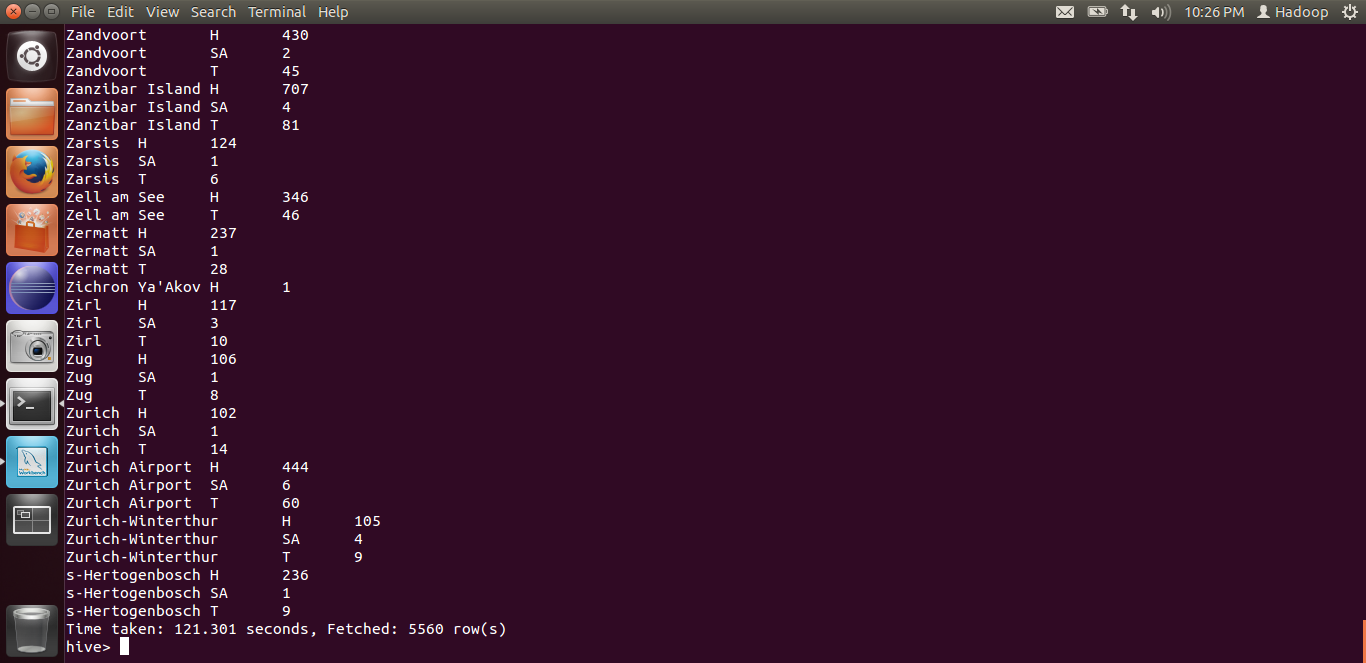
This time, the query was processed in 121.3 seconds. This is because as the number of mappers increase, the data will be divided into more blocks, thus requiring less processing per block. But be cautious here, increasing mappers too much can overkill, resulting in more disk head reads and writes, while CPU sitting idle. It requires some experimentation to determine the correct number of mappers and reducers required for a job.
The experiment showed how Hive can outperform MySQL on the same machine on slow-queries. Repeating the same experiment on multi-node will definitely reduce the time.
So.. what are you waiting for? Go for it...
PS: You may find the screenshots of this post here.
PPS: I would like to thank Nabeel Imam (imam.nabeel@gmail.com) for his helping hand in setting up and carrying out the experiments...
Before you start, make sure you have set up a Hadoop cluster. We will use Hive, a data warehouse to query large data sets and a adequate-sized sample data set, along with an imaginary database of a travelling agency on MySQL; the DB consisting of details about their clients, including Flight bookings, details of bookings and hotel reservations. Their data model is as below:
The number of records in the database tables are as:
- booking: 2.1M
- booking_detail: 2.1M
- booking_hotel: 1.48M
- city: 2.2K
We will write a query that retrieves total country-wise bookings with a hotel reservation, paid in USD or GBP, distributed by booking type for each country.
select c.city_title, d.booking_type, count(*) total from booking b
inner join booking_detail d on d.booking_id = b.booking_id
inner join booking_hotel h on h.booking_id = b.booking_id
inner join city c on c.city_code = d.city_code where b.currency in ('GBP','USD')
group by c.city_code, d.booking_type
This query takes 150 seconds on MySQL to execute. We will try to reduce the query execution time by importing the dataset on Hive and executing the same query on our Hadoop cluster. Here are the steps:
Importing Data
First step is to export the tables in the database CSV files. Open MySQL Workbench in your master (assuming you have MySQL Server and Workbench installed and have exported the data set in it) and execute the following queries:
select * from city into outfile '/tmp/city.csv' fields terminated by ',' lines terminated by '\n';
select * from booking into outfile '/tmp/booking.csv' fields terminated by ',' lines terminated by '\n';
select * from booking_detail into outfile '/tmp/booking_detail.csv' fields terminated by ',' lines terminated by '\n';
select * from booking_hotel into outfile '/tmp/booking_hotel.csv' fields terminated by ',' lines terminated by '\n';
This will export the tables in /tmp directory as CSV files.
Installing Hive
Extract into /home/hadoop/Downloads directory
Start Hadoop services and disable safemode:
$ start-all.sh
$ hadoop dfsadmin -safemode leave
$ jps
Copy Hive binaries and libraries into /usr/local director (or wherever you wish to install):
$ sudo cp -R /home/hadoop/Downloads/hive-0.11.0/ /usr/local/
Create a temporary directory in HDFS and a warehouse directory for Hive:
$ hadoop fs -mkdir /tmp
$ hadoop fs -mkdir /hadoop/hive/warehouse
Assign rights:
$ hadoop fs -chmod g+w /tmp
$ hadoop fs -chmod g+w /hadoop/hive/warehouse
Export environment variable for Hive:
$ export HIVE=/usr/local/hive-0.11.0
Run hive:
$ $HIVE/bin/hive
You should now be in Hive prompt.
Preparing Hive Database
hive>create table booking (booking_id int, currency string, departure_date string, requested_date string) row format delimited fields terminated by ',' stored as textfile;
hive>create table booking_detail (booking_id int, deetails_id int, booking_type string, item_code string, item_name string, passenger_count int, city_code string, duration int, price float, breakfast string, description string) row format delimited fields terminated by ',' stored as textfile;
hive>create table booking_hotel (booking_id int, details_id int, room_type string, room_cat string) row format delimited fields terminated by ',' stored as textfile;
hive>create table city (city_code string, city_title string, country string) row format delimited fields terminated by ',' stored as textfile;
hive>load data local inpath '/tmp/city.csv' overwrite into table city;
hive>load data local inpath '/tmp/booking.csv' overwrite into table booking;
hive>load data local inpath '/tmp/booking_detail.csv' overwrite into table booking_detail;
hive>load data local inpath '/tmp/booking_hotel.csv' overwrite into table booking_hotel;
hive>show tables;
Now execute a query to count the number of records in booking table:
hive>select count(*) from booking;
This will execute a MapReduce job against the given query; the query took 24.5 seconds, which may seem to be surprising to you. This is because the first time, Hive initiates a lot of things, creates some files in temp directory, etc. We will execute the same query again; this time, it took 14.3 seconds. Still, this is very high time for a simple count query. This needs some explanation.
First of all, MySQL and other RDBMSs are optimized to run queries faster using techniques like Indexing, etc. On the other hand, Hive is to run queries on Hadoop framework, which is a distributed computing environment. Therefore, the time it takes to distribute the data, interpret the query, create MapReduce tasks respectively is where the time is consumed most.
Second, a simple count query is not the type of query we should run on distributed environment, as it can easily be handled by RDBMS itself. The real performance impact will be shown when we run a complex query that processes data in large volume.
Now run the same query, which MySQL executed in 150 seconds:
hive>select c.city_title, d.booking_type, count(*) total from booking b inner join booking_detail d on d.booking_id = b.booking_id inner join booking_hotel h on h.booking_id = b.booking_id inner join city c on c.city_code = d.city_code where b.currency in ('GBP','USD') group by c.city_code, d.booking_type;
The query takes 132.84 seconds on single node on Hive. This is because the MapReduce job breaks the original query into pieces, thus leveraging all cores of the CPU to process data in parallel.
We can try the same by increasing number of mappers and reducers. To do so, first quit Hive:
hive>quit;
Shut down Hadoop's services
$ stop-all.sh
Edit the mapred-site.xml file in
$ sudo nano /usr/local/hadoop/conf/mapred-site.xml
Add two properties to the file:
<property>
<name>mapred.map.tasks</name>
<value>20</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>5</value>
</property>
This time, the query was processed in 121.3 seconds. This is because as the number of mappers increase, the data will be divided into more blocks, thus requiring less processing per block. But be cautious here, increasing mappers too much can overkill, resulting in more disk head reads and writes, while CPU sitting idle. It requires some experimentation to determine the correct number of mappers and reducers required for a job.
The experiment showed how Hive can outperform MySQL on the same machine on slow-queries. Repeating the same experiment on multi-node will definitely reduce the time.
So.. what are you waiting for? Go for it...
PS: You may find the screenshots of this post here.
PPS: I would like to thank Nabeel Imam (imam.nabeel@gmail.com) for his helping hand in setting up and carrying out the experiments...
There are lots of information about hadoop have spread around the web, but this is a unique one according to me. The strategy you have updated here will make me to get to the next level in big data. Thanks for sharing this.
ReplyDeleteBig Data Training Chennai
Big Data Training
Big Data Course in Chennai